Se supone que el acelerador de computación «Ponte Vecchio», compuesto por 47 bloques de silicio con un total de más de 100 mil millones de transistores, alimenta supercomputadoras exaflops como la Aurora. En el Día de la Arquitectura, Intel brindó más detalles sobre los próximos procesadores y confirmó que los prototipos de laboratorio lograron más de 45 TFlops de potencia informática con una precisión simple (FP32). Eso es más del doble de lo que puede hacer la Nvidia A100. Además, se dice que el Ponte Vecchio es tan rápido con cálculos FP64 de doble precisión, como lo requiere el estándar Linpack para supercomputadoras Top500, como con el FP32.
Intel también reveló más detalles sobre la generación Xeon SP de Sapphire Rapids que se envía con el Ponte Vecchio. Además, Intel anunció nuevas SmartNIC para centros de datos en la nube, es decir, tarjetas de red para sus unidades de cómputo x86, FPGA o ARM con el fin de mitigar o separar las instancias de servidor de la infraestructura de la nube.
Este es un híbrido de Intel y TSMC

Intel Ponte Vecchio: un acelerador informático consta de hasta 47 chiplets o «mosaicos»
(Foto: Intel)
Como ya se sabe, Intel empareja varias matrices para Ponte Vecchio de su propia producción y del proveedor TSMC: a una base de 640 milímetros cuadrados, Intel empareja otras matrices con procesos internos EMIB y Foveros, y en ocasiones varios moldes se colocan uno encima del otro. (pilas). El almacenamiento en pila HBM2e también está conectado directamente.
Al contrario de lo que se esperaba anteriormente, Intel no fabrica «Compute Tiles» con hasta ocho núcleos Xe HPC y 4 MByte L1 de caché cada uno. Dos de estos cuadrados de cálculo forman un segmento de cálculo Xe HPC con 8 núcleos Xe y 8 MByte de caché L1. Además, hay hasta 144 MB de caché L2 en el mosaico base, fabricado con tecnología «Intel 7» de 10 nm.
Los cuadrados adicionales equipados con tecnología TSMC-N7 proporcionan ocho enlaces denominados Xe por procesador Ponte Vecchio. Esto permite conectar hasta ocho Ponte Vecchios directamente entre sí. Para los nodos de servidor de la supercomputadora Aurora, Intel utiliza seis Ponte Vecchios, cada uno conectado entre sí mediante enlaces Xe. Está vinculado a dos Sapphire Rapids Xeons a través de PCIe 5.0 o mediante Compute Express Link CXL 1.1, que se basa en PCIe 5.0.
Los núcleos Xe HPC son diferentes de Xe HPG


Intel Xe-HPC-Core
(Foto: Intel)
Los núcleos Xe-HPC (HPC significa High Performance Computing) contienen esencialmente los mismos núcleos vectoriales, matriciales y de trazado de rayos que los núcleos Xe-HPG para juegos de alto rendimiento. Pero los motores matriciales y vectoriales para núcleos HPC manejan formatos de datos «más amplios», es decir, vectores de 512 bits y matrices de 4096 bits. El núcleo Xe-HPC contiene ocho unidades vectoriales y ocho matrices, además de una caché L1 de 512 KB.
Zion – SP Sapphire Rapids
Como se ha especulado hasta ahora, el próximo Sapphire Rapids (SPR) Xeon constará de cuatro cuadrados, cada uno con varios núcleos de CPU «Golden Cove», que también se utilizan en Alder Lake, pero uno para la Server Enhanced Edition con más caché. Intel aún no ha revelado cuántos núcleos hay por mosaico o CPU. Los rumores dicen que es 56 (14 por mosaico), que aún sería más bajo que el AMD Epyc 7003 Milán (64) e incluso más bajo que el AMD Genoa esperado en 2022 con 96 o incluso 128 en Bérgamo.
Sin embargo, las nuevas calculadoras AMX prometen poderosos aumentos en la potencia informática de la IA.
Intel confirmó que cada mosaico tiene un controlador de memoria para dos canales DDR5 SDRAM; Por lo tanto, hay ocho canales de RAM por CPU, también para las unidades Optane 300. Además, los SPR-Xeons vienen con una pila HBM montada en una brida, que también se puede usar simultáneamente con la RAM DDR5. AMD quiere conectar hasta 12 canales de RAM con Génova.
Intel ya ha destacado PCIe 5.0 con CXL 1.1 varias veces para SPR. Pero Ultra Path Interconnect (UPI) también se ha acelerado; Como antes, permite emparejar hasta ocho procesadores (servidor de ocho sockets, 8S).
IPU también con ARM Neoverse
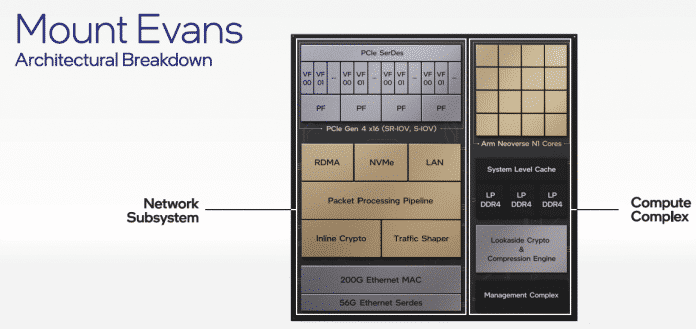
El «Mount Evans» de Intel IUP también tiene 16 núcleos ARM
(Foto: Intel)
Las SmartNIC, o unidades de procesamiento de datos (DPU), que aligeran los núcleos de la CPU en los servidores y manejan tareas de infraestructura como la red, el almacenamiento y el cifrado, son particularmente interesantes para los proveedores de servicios en la nube. Intel está hablando de Unidades de procesamiento de infraestructura (IPU) y anunció tres nuevas: Oak Springs Canyon (Agilex-FPGA más Xeon D), Arrow Creek (Agilex-FPGA y Max10-FPGA) y Mount Evans. Se supone que este último también maneja Ethernet de 200 Gbit / sy contiene 16 núcleos ARM Neoverse N1.


(una línea)

«Alborotador. Amante de la cerveza. Total aficionado al alcohol. Sutilmente encantador adicto a los zombis. Ninja de twitter de toda la vida».





